
從黃仁勳推出了NemoClaw,Nvidia版本的”小龍蝦”之後,相信開始有一堆人在網路上洗各種小龍蝦有多厲害的文章,號稱可以幫你自動整理行事曆、幫你看Email、幫你找最便宜的購物點之類之類,講得很神。但是你真的知道小龍蝦 OpenClaw 是什麼嗎?本文從 OpenClaw 的起源和它是什麼、一般人要如何控制 OpenClaw 的風險、如何安全且低成本的安裝/使用、到後續的備份及復原一次講完。
在本文中,我們把OpenClaw稱為小龍蝦,台灣常見的用語。小龍蝦AI指的是OpenClaw,一個可以在本地環境中自主執行任務的Agentic AI系統。除了這個之外,常見的還有NanoClaw、IronClaw、OpenFang、LocalAGI、以及NemoClaw等等各式各樣的變種。
在最開始之前,這裡是我們的警語部份:
警語:OpenClaw的主要意圖是快速的完成您給的任務,但是請把關不要把自己的重要帳號、密碼直接明文傳給小龍蝦,本文可以教你如何安全使用,但是使用者自己要自爆,筆者也沒有辦法。
前情提要:
讓小龍蝦維持健康 上集 - 有Nvidia或AMD GPU並且VRAM超過1GB
接下來,我們需要設定Memory Search,OpenClaw跟直接使用ChatGPT最大的差異,就在小龍蝦記得你,記得跟你的一切記憶。晚點我們會談到Context Window,但是在這之前,我們先把Memory Search (記憶搜尋) 設定起來。
在開始之前,我們先需要看一下本機是否有一顆小小的GPU可以使用。如果有的話,可以大幅加快記憶搜尋的速度。如果您是Nvidia GPU,請用以下多段式指令安裝,直接在終端機裡複製貼上:
安裝Nvidia驅動程式
# === 0. 清掉舊的 NVIDIA driver(避免鬼打牆)===
sudo apt purge -y '*nvidia*'
sudo apt autoremove -y
# === 1. 安裝必要編譯環境 ===
sudo apt update
sudo apt install -y build-essential dkms linux-headers-$(uname -r)
# === 2. 安裝 Ubuntu 建議的 NVIDIA driver ===
sudo ubuntu-drivers autoinstall
# === 3.(可選但建議)安裝 CUDA toolkit ===
sudo apt install -y nvidia-cuda-toolkit
# === 4. 提醒:這裡一定要重開機 ===
echo ">>> 請現在手動 reboot,回來再執行驗證指令 "
檢查Nvidia驅動程式運作正常
# === 5. 驗證 NVIDIA driver ===
nvidia-smi
# === 6. 驗證 CUDA(可選)===
nvcc --version || echo "CUDA toolkit not found (OK if you didn't install it)"
# === 7. 驗證 GPU 計算能力(簡單版)===
python3 - 'EOF'
import torch
print("CUDA available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("GPU:", torch.cuda.get_device_name(0))
EOF
如果是 AMD GPU 使用者,前面這招過不了關,請自行處理安裝問題,ROCm的安裝限定型號,而且支援LLM效果有限。裝的起來是好命的,裝不起來,麻煩您直接跳下一節。
https://www.amd.com/zh-tw/support/download/linux-drivers.html
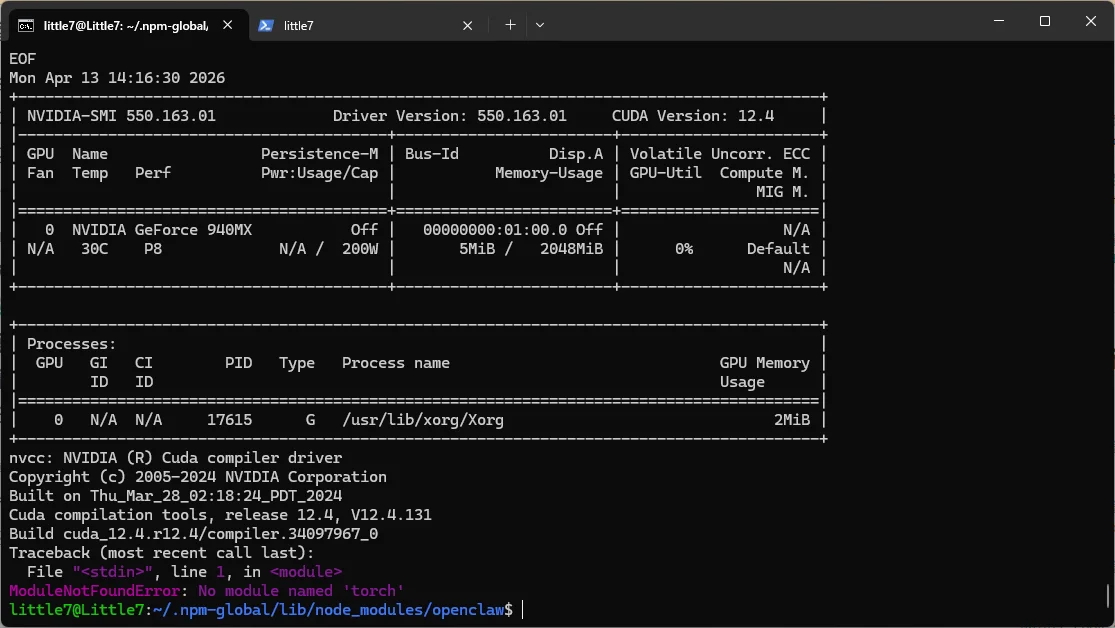
▲有個GPU事情就好辦了。尤其是還有2048MiB(也就是2GB VRAM),對於我們要用的llama nomic-embed-text-v1.5.Q4_K_M.gguf 這種吃接近1GB VRAM的小模型來說,根本就是超豪華吃到飽套餐。
讓小龍蝦維持健康 下集 - 安裝 Ollama 模型做記憶體搜尋(不論有沒有GPU)
接下來,不論您的小龍蝦OpenClaw是否有正常的把GPU啟動,都是建議使用 Ollama embeddinggemma模型來處理Memory Search。否則用個幾天,小龍蝦OpenClaw會真的很瞎,完全忘記我們前幾天講過的話。
安裝Ollama模型不難,只要在終端機下把以下指令複製貼上:
# === 0. 安裝 Ollama(官方 Linux 安裝方式) ===
curl -fsSL https://ollama.com/install.sh | sh && \
# === 1. 啟動 Ollama(若已在跑,這行不影響太多) ===
( pgrep -x ollama >/dev/null || nohup ollama serve >/tmp/ollama.log 2>&1 & ) && \
sleep 5 && \
# === 2. 拉一顆適合 memory search 的小型 embedding 模型 ===
ollama pull embeddinggemma && \
# === 3. 先直接測 Ollama embeddings API 有沒有活著 ===
curl -s http://localhost:11434/api/embed -d '{
"model": "embeddinggemma",
"input": "Little7 local memory test"
}' && echo && \# === 4. 把 OpenClaw 的 memory search 切到 Ollama ===
openclaw config set agents.defaults.memorySearch.enabled true && \
openclaw config set agents.defaults.memorySearch.provider ollama && \
openclaw config set agents.defaults.memorySearch.model embeddinggemma && \
openclaw config set agents.defaults.memorySearch.fallback none && \# === 5. 順手把 compaction 緩衝拉高,避免還沒用多久就爆Context ===
openclaw config set agents.defaults.compaction.reserveTokensFloor 30000 && \
openclaw config set agents.defaults.compaction.memoryFlush.softThresholdTokens 12000 && \# === 6. 重建 memory index 並驗證 ===
openclaw memory index --force && \
openclaw memory status --deep# === 7. 確認未來重開機後Ollama服務會自動啟動並驗證 ===
sudo systemctl enable --now ollama
sudo systemctl status ollama --no-pager
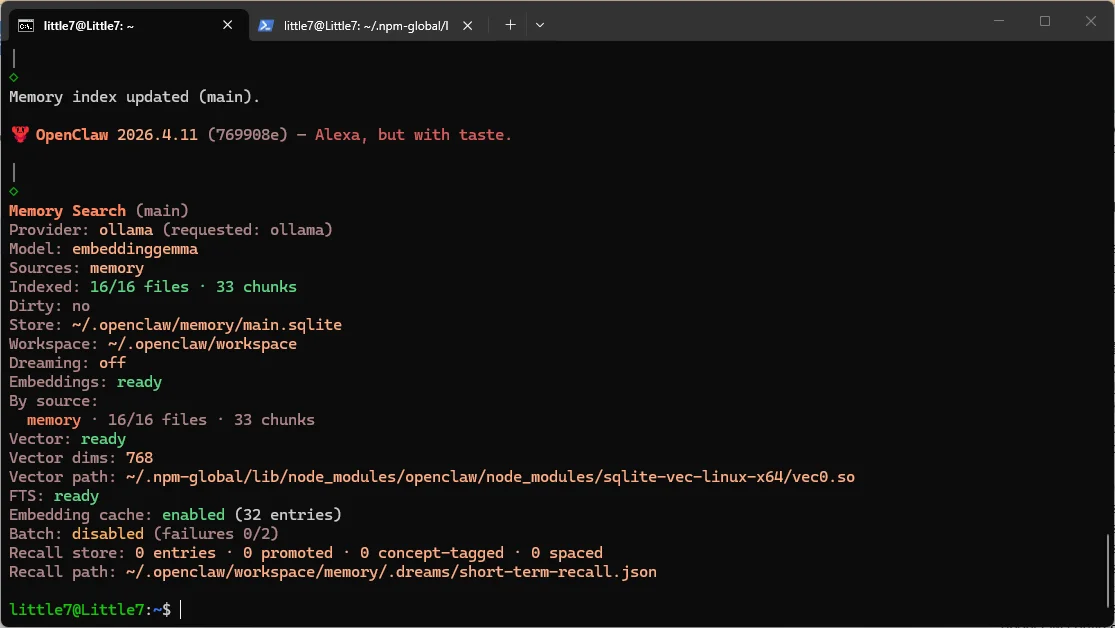
’▲設定完成本機記憶搜尋能力之後,從此省下每天USD 1.36的記憶體搜尋費。












